import sklearn
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
print(sklearn.__version__) # 사이킷런 버전확인
#붓꽃 데이터 세트를 로딩
iris=load_iris()
#iris.data는 Iris 데이터 세트에서 피처(feature)만으로 된 데이터를 numpy로 가지고 있음.
iris_data=iris.data # x값 들
#iris.target은 붓꽃 데이터 세트에서 레이블(결정 값)데이터를 numpy로 가지고 있다.
iris_label=iris.target #y값 들
print('iris target값:', iris_label)
print('iris target명:', iris.target_names) # ['setosa' 'versicolor' 'virginica'] 문자타입을 0, 1, 2숫자로 변환!
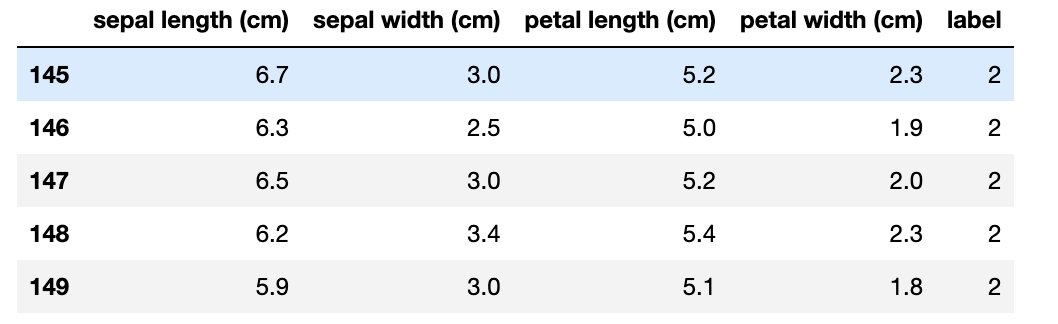
#붓꽃 데이터 세트를 자세히 보기 위해 DataFrame으로 변환한다.
iris_df = pd.DataFrame(iris_data,columns=iris.feature_names)
iris_df['label']=iris.target
iris_df.tail()
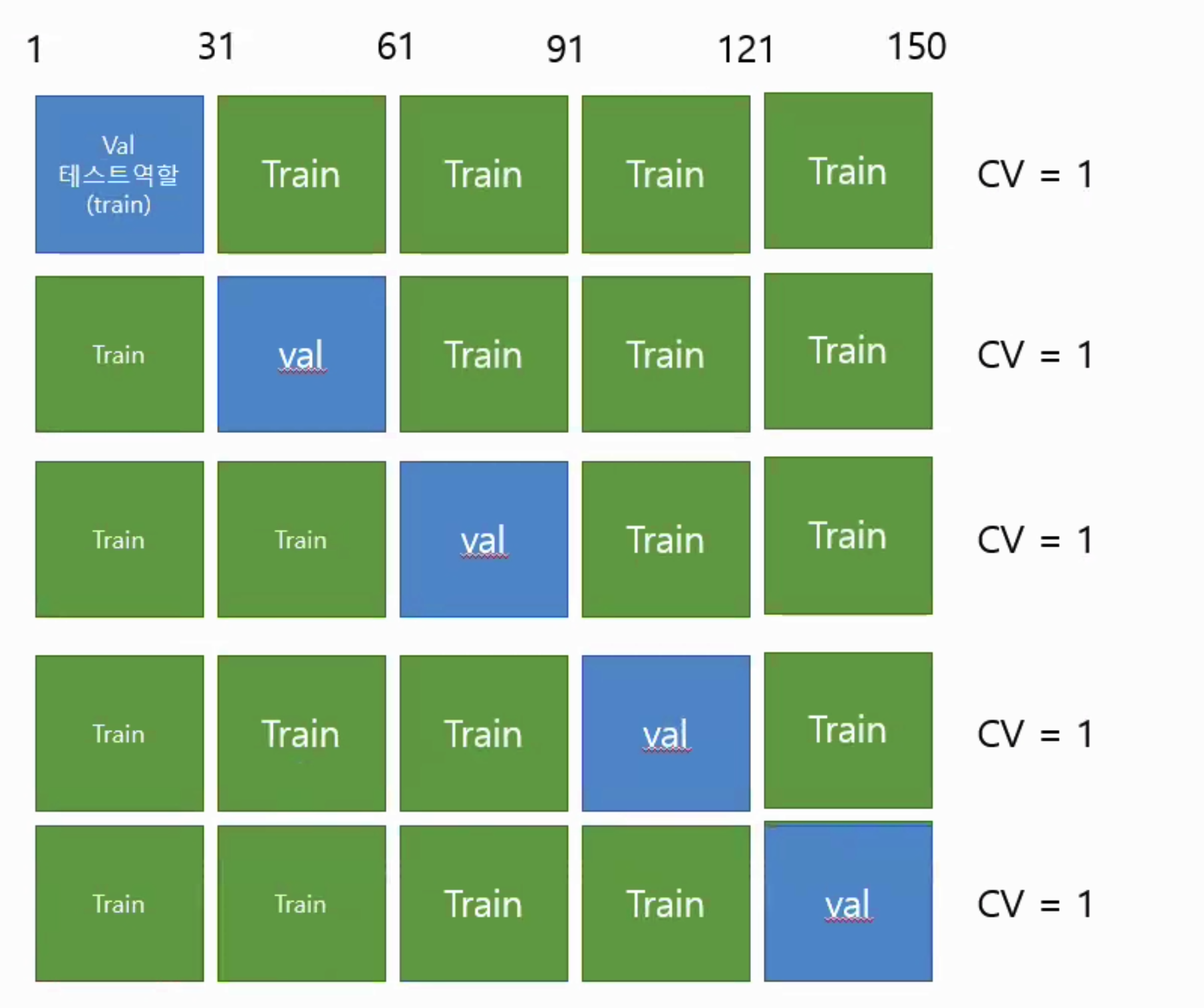
다음으로 학습용 데이터와 테스트용 데이터를 분리해보자. 학습용 데이터와 테스트용 데이터는 반드시 분리해야 한다.
학습데이터로 학습된 모델이 얼마나 뛰어난 성능을 가지는지 평가하려면 테스트 데이터 세트가 필요하기 때문이다.
이를 위해 사이킷런은 train_test_split()API를 제공한다. train_test_split()을 이용하면 학습 데이터와 테스트 데이터를 test_size 파라미터 입 값의 비율로 쉽게 분할이 가능하다. 예를 들어 test_size =0.2로 입력 파라미터를 설정하면 전체 데이터 중 테스트 데이터가 20%, 학습데이터가 80%로 데이터를 분할한다. 먼저 train_test_split()을 호출한 후 좀 더 자세히 입력 파라미터와 변환값을 살펴보자.