이런 경우 실행중인 Containers > Files로 접근하여서 home > node > .openclaw > openclaw:json 을 우측 클릭하여 edit file
쭉내리면 gateway 설정이있다
{
"gateway": {
"bind": "0.0.0.0", // <--- 여기가 루프백으로 되어 있다면 무조건 0.0.0.0으로 수정! 또는 "lan" 으로 수정
"port": 18789,
"controlUi": {
"allowInsecureAuth": true // <--- 이 설정이 있어야 브라우저 접속을 허용됨
}
}
}
8 Pairing
마지막으로 openclaw dashboard 입력하거나 설치가 다 끝나면 링크+토큰 번호를 주는데 해당 링크를 누르면 이렇게 뜸
docker exec -it {컨테이너이름} dist/index.js devices list
# Particle CLI
bash <( curl -sL https://particle.io/install-cli )
# 업데이트 진행
particle update-cli
# 버전확인
particle --version
2. 장비 프로그램 모드 전환
# 전원버튼 3초이상 꾹 누르면 노란색으로 LED 바뀜
# usb 확인
particle usb configure
# Tachyon 설치
particle tachyon setup
# 단계 쭈욱 이어가면됨!
# 설치가 다되면 이렇게 뜸
All done! Your Tachyon device is ready to boot to the desktop and will automatically connect to Wi-Fi.
To continue:
- Disconnect the USB-C cable
- Connect a USB-C Hub with an HDMI monitor, keyboard, and mouse.
- Power off the device by holding the power button for 3 seconds and releasing.
- Power on the device by pressing the power button.
When the device boots it will:
- Activate the built-in 5G modem.
- Connect to the Particle Cloud.
- Run all system services, including the desktop if an HDMI monitor is connected.
Learn more about Tachyon at our developer site: https://developer.particle.io/tachyon
View your device on the Particle Console at: https://console.particle.io/tachyon-번호/devices/장비번호
# 다시 부팅하면
전원 led가 보라색으로 뜰거임
2022년에 작성된 글인데 3년동안 똑같이 장사를 하고 있다는건? 도대체 해당기관은 뭐하고 있음?
그래 일단 저 블로그 작성자의 말 또한 온전히 믿을 수 없다. 내가 상품을 받아본 것이 아니기 때문에, 우선 정말 가품을 판매하는지부터, 그리고 왜 저 사이트가 3년 동안 무사히 운영될 수 있었는지 파헤치려고 한다. 분명 나처럼 시도한 사람들의 후기를 보고 싶었는데 딱히 없어서 내가 시도해봄.
우선 상품을 구매하기 전에 가품을 받으면 어떻게 되냐고 물어보았다. 애네들 구조를 보아하니 “나 오픈마켓이라 판매자들이 판매하는 거고 나는 중간에서 중개만 했을 뿐이야!” 라는 식으로 꼬리 자르기를 하려는 구조인 듯함.
이때부터 느낌이 쎄함을 느낌 ㅋㅋㅋ
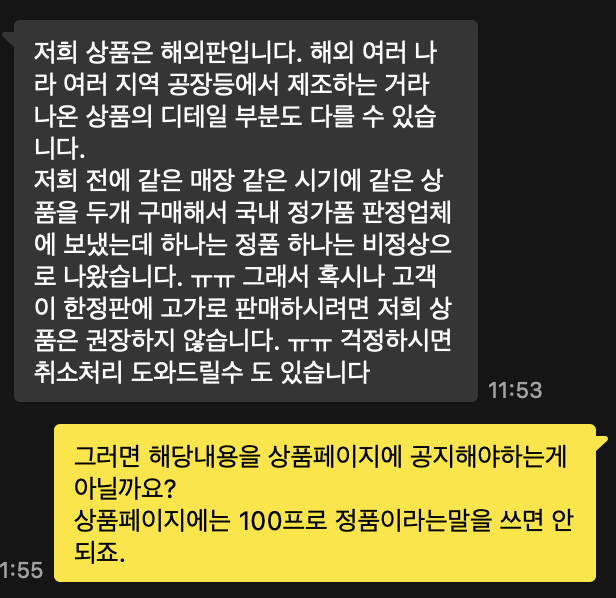
판매사이트에 정품만 파냐고 문의한 내용의 답변
그래서 직접 판매하는 판매처의 연락처를 알아내서 그 쪽으로 문의를 진행하였더니 더 가관이였다.
"이전에 정품 하나는 비정상적으로 나왔습니다" 그럼 그게 정품이 아닌거잖아? 왜 정품이라는 표현을 쓰는거지?
그래서 상품페이지에 100% 정품이라는 말을 쓰지말랬더니 참고하겠다고 한다 (안바꾸겠다는 소리임)
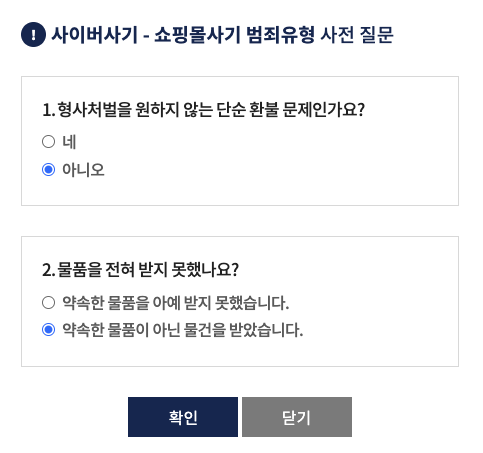
12/15일 사건담당자는 가품소견서가 없으면 진행할 수 없다고 함. 나는 가품소견서를 받고싶은데 대부분 고가의 상품만 가품확인을 해주어서 업체를 찾지못했다고 말하자, 그냥 취하하라고 한다. 이해는 된다... 형사 입장에서는 얼마나 많은 더 우선순위인 일들이 있을까? 결국 왜 한국에 사기꾼들이 판을 치고 돌아다니는지 시장경제와 공무원들의 업무 이해관계를 보아 바로 이해할 수 있었다.
근로자 수가 10명 미만인 사업에 고용된 근로자 중 월평균보수가 270만원 미만인신규가입 근로자와 그 사업주
2021년부터는 신규가입자에 대해서만 지원
2. 지원수준 및 지원기간
(지원수준) 신규가입 근로자 및 사업주가 부담하는 고용보험과 국민연금 보험료의 80%
* 고용보험의 경우 근로자는 월 최대 16,560원, 그 사업주는 월 최대 21,160원까지 지원하며, 국민연금의 경우 근로자와 그 사업주는 각각 월 최대 82,800원까지 지원
(지원기간) 2018년 1월 1일부터 신규가입자 및 기가입자 지원을 합산하여 36개월까지만 지원
3. 지원 제외대상
지원 대상에 해당하는 근로자가 아래의 어느 하나라도 해당되는 경우에는 지원 제외됩니다.
지원신청일이 속한 보험연도의 전년도 재산의 과세표준액 합계가6억원 이상인 자
지원신청일이 속한 보험연도의 전년도(소득자료 입수 시기에 따라 보험연도의 전년도 또는 전전년도) 종합소득이4,300만원 이상인 자
4. 보험료 지원방법
두루누리 사회보험료 지원을 신청하면 사업주가 월별보험료를 법정기한 내에 납부하였는지를 확인하여 완납한 경우 그 다음 달 보험료에서 해당 월의 보험료 지원금을 뺀 나머지 금액을 고지하는 방법으로 지원하고 있습니다. (다만, 그 다음 달에 부과될 보험료가 없는 경우에는 해당 월의 지원금은 지원하지 않음)
두루누리 사회보험료의 경우 지원신청일이 속한 달의 고용보험료부터 해당 보험연도 말까지 지원하되, 보험연도 말 현재 고용보험료 지원을 받고 있고 그 보험연도 중 보험료 지원기간의 월평균 근로자인 피보험자 수가 10명 미만인 경우에는 다음 보험연도에 별도로 신청하지 않더라도 계속 지원을 받으실 수 있습니다. 다만, 고용보험료의 경우 사업주가 보수총액신고 또는 피보험자격 취득신고를 법정기한 내에 하지 않은 경우에는 그 신고를 이행한 날이 속한 달의 고용보험료부터 지원하고, 지원대상이 되는 근로자인 피보험자가 일용근로자인 경우에는 사업주가 법정기한 내에 제출한 달의 '근로내용 확인신고서'에 기재된 사람에 대한 월별보험료만을 지원합니다.
5. 지원금액 산정 예시
사업주지원금(신규가입자의 경우)
근로자 수 10명 미만인 사업에 고용된 근로자의 월평균보수가 230만원이라면 매월 103,960원을 지원 받을 수 있습니다.(80% 지원)
근로자지원금(신규가입자의 경우)
근로자 수 10명 미만인 사업에 고용된 근로자의 월평균보수가 230만원이라면 매월 99,360원을 지원 받을 수 있습니다.(80% 지원)
참고사항
근로자 수가 ‘10명 미만인 사업’이란?
지원신청일이 속한 보험연도의 전년도에 근로자인 피보험자 수가 월평균 10명 미만이고, 지원신청일이 속한 달의 말일을 기준으로 10명 미만인 사업
지원신청일이 속한 보험연도의 전년도 근로자인 피보험자 수가 월평균 10명 이상이나 지원 신청일이 속한 달의 직전 3개월 동안 (지원신청일이 속한 연도로 한정함) 근로자인 피보험자 수가 연속하여 10명 미만인 사업
지원신청일이 속한 보험연도 중에 보험관계가 성립된 사업으로 지원신청일이 속한 달의 직전 3개월 동안(지원신청일이 속한 연도로 한정하며, 보험관계성립일 이후 3개월이 지나지 아니한 경우에는 그 기간 동안) 근로자인 피보험자 수가 연속하여 10명 미만인 사업
* 근로자 수 산정 시 출산전후휴가, 유산ㆍ사산 휴가, 육아휴직 또는 육아기 근로시간 단축에 해당하는 근로자는 제외하고 산정함
* 법인은 법인등록번호, 개인은 사업자등록번호 단위로 사업 규모를 판단함
* 「부패방지 및 국민권익위원회의 설치와 운영에 관한 법률」 제2조 제1호에 따른 공공기관은 10명 미만인 사업에 해당하여도 지원대상에서 제외함