728x90
1. 순서가 없는 범주형 데이터
import numpy as np
from sklearn.preprocessing import LabelBinarizer, MultiLabelBinarizer
feature = np.array((['가나다라'],
['가나다라'],
['아바하자'],
['카나다사']))
print(feature)
# 원-핫 인코더 생성
one_hot = LabelBinarizer()
one_hot.fit_transform(feature) # 특성을 원-핫 인코딩 변환
# 특성 클래스 확인
print(one_hot.classes_)
"""
[['가나다라']
['가나다라']
['아바하자']
['카나다사']]
['가나다라' '아바하자' '카나다사']
"""
2. 다중 클래스 특성에 대한 처리
multiclass_feature = [('가나다라마','아자바하나'),
('자다가나라','자다나타하'),
('가나다라마','아자바하나'),
('아마자나가','아카나다하'),
('가나다라마','아자바하나'),
]
one_hot_mult = MultiLabelBinarizer()
one_hot_mult.fit_transform(multiclass_feature)
print(one_hot_mult.classes_)
# ['가나다라마' '아마자나가' '아자바하나' '아카나다하' '자다가나라' '자다나타하']
3. 문자 타깃 데이터 원-핫 인코딩
from sklearn.preprocessing import OneHotEncoder
str_feature = ([['안녕', 1],
['저녁', 2],
['안녕', 1],
['점심', 3],
])
one_hot_encoder = OneHotEncoder(sparse=False)
# One hot encoder -> 입력 특성 배열을 모두 범주형
one_hot_encoder.fit_transform(str_feature)
print(one_hot_encoder.categories_)
# [array(['안녕', '저녁', '점심'], dtype=object), array([1, 2, 3], dtype=object)]4. 순서가 있는 범주형 특성 인코딩
- 순서가 있는 클래스는 순서 개념을 가진 수치값으로 변환
- 딕셔너리 사용해서 -> 특성
import pandas as pd
# 특성 데이터 생성
dataframe = pd.DataFrame({
'Score' : ["Low", "Low", "Medium", "Medium", "High"]
})
print(dataframe)
"""
Score
0 Low
1 Low
2 Medium
3 Medium
4 High
"""
# 매핑 딕셔너리 생성
scale_mapper = {
"Low" : 1,
"Medium" : 2,
"High" : 3
}
print(scale_mapper)
# {'Low': 1, 'Medium': 2, 'High': 3}
data = dataframe["Score"].replace(scale_mapper)
print(data)
"""
0 1
1 1
2 2
3 2
4 3
Name: Score, dtype: int64
"""4-2. 순서가 있는 범주형 특성 인코딩
from sklearn.preprocessing import OrdinalEncoder
feature_array = np.array((['Low', 10],
['High', 40],
['Medium',3],))
ordinal_encoder = OrdinalEncoder()
ordinal_encoder.fit_transform(feature_array)
print(ordinal_encoder.categories_)
# [array(['High', 'Low', 'Medium'], dtype='<U21'), array(['10', '3', '40'], dtype='<U21')]4-3. 순서가 있는 범주형 특성 인코딩
- 특성 딕셔너리 인코딩
from sklearn.feature_extraction import DictVectorizer
# 딕셔너리 생성
data_dict =[{"Red" : 2 , "Blue" : 4},
{"Red" : 4 , "Blue" : 3},
{"Red" : 1 , "Yellow" : 2 },
{"Red" : 1 , "Yellow" : 2}]
dictVectorizer = DictVectorizer(sparse=False)
feature_dict = dictVectorizer.fit_transform(data_dict)
print(feature_dict)
feature_dict_name = dictVectorizer.get_feature_names()
print(feature_dict_name)
dict_data = pd.DataFrame(feature_dict, columns=feature_dict_name)
print(dict_data)
"""
[[4. 2. 0.]
[3. 4. 0.]
[0. 1. 2.]
[0. 1. 2.]]
['Blue', 'Red', 'Yellow']
Blue Red Yellow
0 4.0 2.0 0.0
1 3.0 4.0 0.0
2 0.0 1.0 2.0
3 0.0 1.0 2.0
"""
범주형 데이터 - 누락된 클래스값 대처하기 1
- knn으로 주변 그룹을 활용하여 nan의 값 예측함
from sklearn.neighbors import KNeighborsClassifier
x = np.array([[0, 2.10, 1.48],
[1,1.18,1.33],
[0,1.22,1.27],
[1, -0.20, -1.15]])
x_with_nan = np.array([[np.nan, 0.87, 1.33], [np.nan, -0.67, -0.22]]) # 일부러 nan 생성
clf = KNeighborsClassifier(3, weights='distance')
print(x[:,1:])
print(x[:,0])
"""
[[ nan 0.87 1.33]
[ nan -0.67 -0.22]]
[[ 2.1 1.48]
[ 1.18 1.33]
[ 1.22 1.27]
[-0.2 -1.15]]
[0. 1. 0. 1.]
"""train_model = clf.fit(x[:,1:], x[:,0])
imputer_values = train_model.predict(x_with_nan[:,1:]) # 누락된 값의 클래스 예측
x_with_imputer = np.hstack((imputer_values.reshape(-1,1), x_with_nan[:,1:]))
data = np.vstack((x_with_imputer, x)) # 두 특성 행렬을 연결
print(data)
"""
[[ 0. 0.87 1.33]
[ 1. -0.67 -0.22]
[ 0. 2.1 1.48]
[ 1. 1.18 1.33]
[ 0. 1.22 1.27]
[ 1. -0.2 -1.15]]
"""
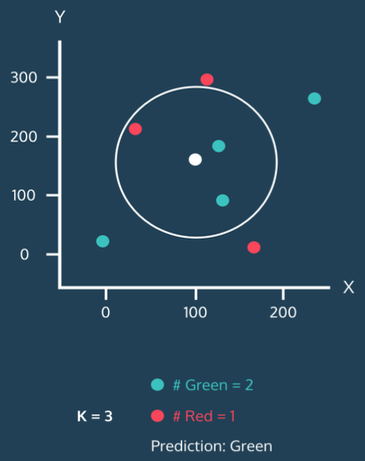
근처의 값을 비교해서 주변 그룹에 많이 있는 라벨을 따라감
범주형 데이터 - 누락된 클래스값 대처하기 2
- 누락된 값을 특성에서 가장 자주 등장하는 값으로 채우기
from sklearn.impute import SimpleImputer
x_complete = np.vstack((x_with_nan, x))
print("전")
print(x_complete)
impute = SimpleImputer(strategy='most_frequent')
data_impute = impute.fit_transform(x_complete)
print("후")
print(data_impute)
"""
전
[[ nan 0.87 1.33]
[ nan -0.67 -0.22]
[ 0. 2.1 1.48]
[ 1. 1.18 1.33]
[ 0. 1.22 1.27]
[ 1. -0.2 -1.15]]
후
[[ 0. 0.87 1.33]
[ 0. -0.67 -0.22]
[ 0. 2.1 1.48]
[ 1. 1.18 1.33]
[ 0. 1.22 1.27]
[ 1. -0.2 -1.15]]
"""728x90
'AI > [Preprocessing]' 카테고리의 다른 글
| [전처리] 이미지 비율에 맞게 정사각형 만들기 (0) | 2023.06.15 |
|---|---|
| [전처리] 가져온 사진 정보 받기 (feat, xml) (1) | 2023.06.15 |
| [전처리] 가져온 사진 정보 받기 (feat, json) (0) | 2023.06.14 |
| [전처리] 폴더에 있는 사진 가져오기 (0) | 2023.06.14 |
| [전처리] 손글씨 데이터 PCA 적용예시 (1) | 2023.06.06 |